面向现代数据湖的 RustFS
现代数据湖和数据湖仓一体架构建立在现代对象存储之上。这意味着它们可建立在 RustFS 之上。
RustFS 为现代数据湖/湖仓一体提供统一的存储解决方案,可以在任何地方运行:私有云、公共云、机柜、裸金属 ―― 甚至可以在边缘。是的,快速、可扩展、云原生且随时可用 ―― 内置电池。
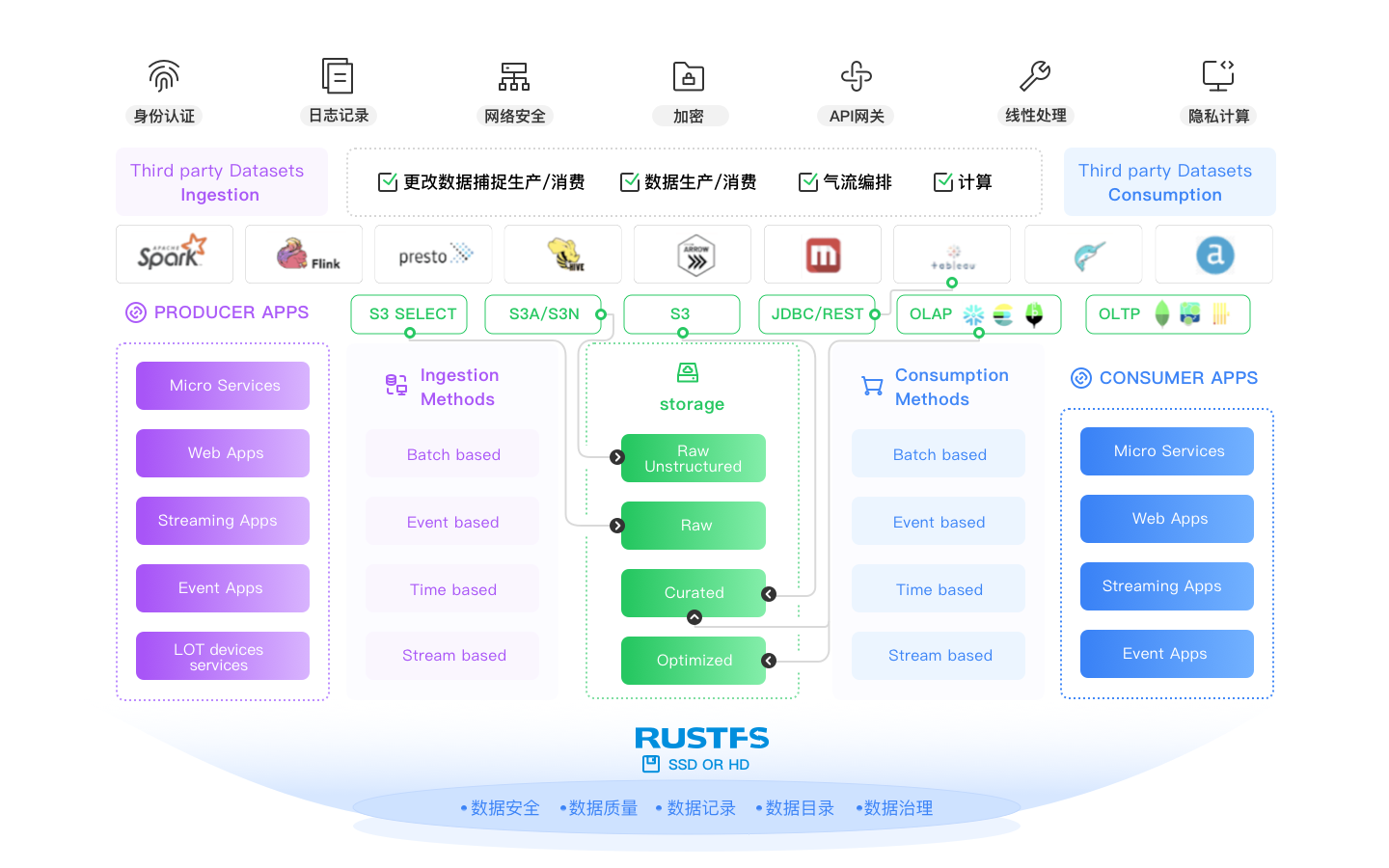
开放表格格式就绪
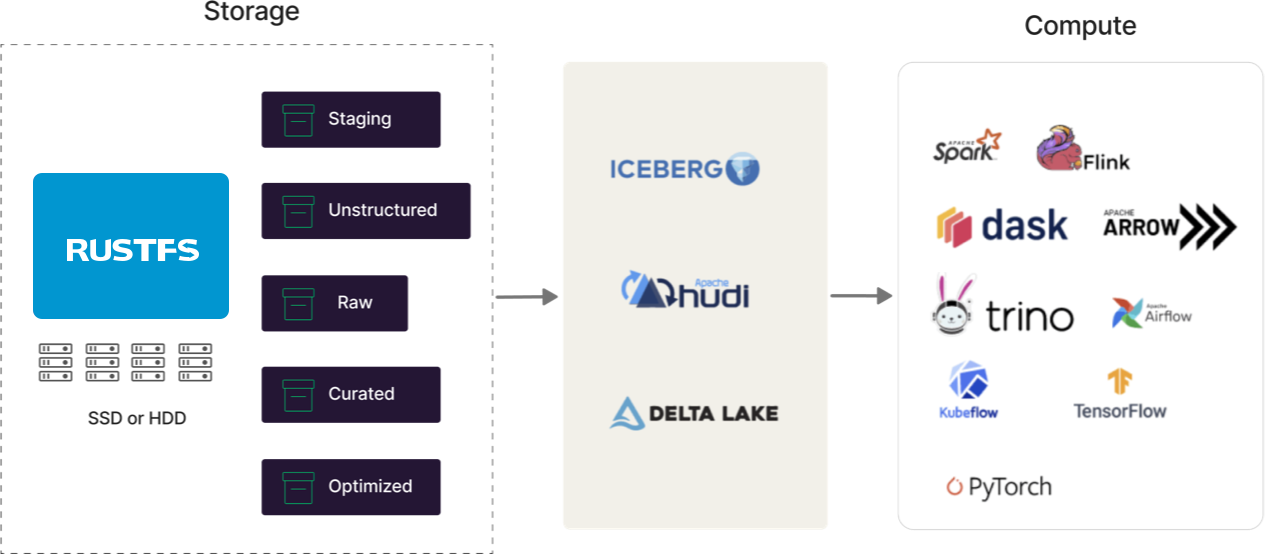
现代数据湖是多引擎的,这些引擎(Spark、Flink、Trino、Arrow、Dask 等)都需要在一个连贯的架构中绑定在一起。现代数据湖必须提供中央表存储、可移植元数据、访问控制和持久结构。这就是 Iceberg、Hudi 和 Delta Lake 等格式发挥作用的地方。它们是为现代数据湖设计的,而 RustFS 支持每一个。我们可能对哪一个会胜出有自己的看法(你随时可以问我们...),但我们致力于支持它们,直到这样做不再有意义(参见 Docker Swarm 和 Mesosphere)。
云原生
RustFS 出生于云端,并基于云原则运行 —— 容器化、编排、微服务、API、基础设施即代码和自动化。正因如此,云原生生态系统与 RustFS "无缝协作" —— 从 Spark 到 Presto/Trino,从 Snowflake 到 Dremio,从 NiFi 到 Kafka,从 Prometheus 到 OpenObserve,从 Istio 到 Linkerd,从 Hashicorp Vault 到 Keycloak。
不要只听我们的说法 —— 输入你最喜欢的云原生技术,让 Google 提供证据。
多引擎
RustFS 支持所有 S3 兼容的查询引擎,也就是说全部支持。没看到你使用的那个?联系我们,我们会进行调查。


性能
现代数据湖需要具备一定性能水平,更重要的是,需要具备传统 Hadoop 时代通用存储设备所无法想象的规模化性能。RustFS 在多个基准测试中已证明其性能优于 Hadoop,且迁移路径已有详细文档记录。这意味着查询引擎(Spark、Presto、Trino、Snowflake、Microsoft SQL Server、Teradata 等)性能更佳。这同样适用于您的 AI/ML 平台——从 MLflow 到 Kubeflow。
我们公开发布我们的基准测试结果,并确保其可重复性。本文将介绍我们如何仅使用 32 个现成的 NVMe SSD 节点,在 GET 操作上达到 325 GiB/s(349 GB/s),在 PUT 操作上达到 165 GiB/s(177 GB/s)。
轻量
RustFS 的服务器二进制文件整体小于 100 MB。尽管它功能强大得足够健壮可以在数据中心运行,但它同时也足够小巧以至于可以在边缘舒适地运行。在 Hadoop 世界中没有这样的替代方案。对于企业而言,这意味着您的 S3 应用程序可以通过相同的 API 在任何地方访问数据。通过实现 RustFS 边缘位置和复制功能,我们可以在边缘捕获和过滤数据,并将其交付到父集群以进行聚合和进一步的分析实现。
分解
现代数据湖扩展了打破 Hadoop 的分解能力。现代数据湖具有高速查询处理引擎和高吞吐量存储。现代数据湖规模太大,无法适应数据库,因此数据驻留在对象存储中。这样,数据库可以专注于查询优化功能,并将存储功能外包给高速对象存储。通过将数据子集保留在内存中,并利用谓词下推(S3 Select)和外部表等特性,查询引擎具有更大的灵活性。
开源
采用 Hadoop 的企业是出于对开源技术的偏好。作为逻辑上的继承者 —— 企业也希望他们的数据湖是开源的。这就是 Iceberg 兴盛的原因,也是 Databricks 开源 Delta Lake 的原因。
软件能力、无锁定的自由、以及自成千上万用户支持所带来的放心,都具有实实在在的价值。RustFS 也是 100% 开源的,确保组织在投资现代数据湖时能够坚持其目标。
迅速猛增
数据在不断生成,这意味着必须不断进行数据摄取 —— 而又不会造成消化不良。RustFS 就是为这样的世界而构建的,并且可以开箱即用地与 Kafka、Flink、RabbitMQ 以及众多其他解决方案协同工作。其结果是,数据湖/数据湖屋变成了一个可以无缝扩展至艾字节及以上的单一事实来源。
RustFS 拥有多家客户,其每日数据摄入量超过 250PB。
简洁性
简洁并不容易。它需要工作、纪律,最重要的是,承诺。RustFS 的简洁性是传奇的,这是一个哲学上的承诺,使我们的软件易于部署、使用、升级和扩展。现代数据湖不必复杂。有几个部分,我们致力于确保 RustFS 是最易于采用和部署的。
ELT 或 ETL ―― 它只是有效工作
RustFS 不仅适用于所有数据流协议,还适用于所有数据处理管道——所有数据流协议和数据处理管道都与 RustFS 兼容。所有供应商都经过广泛测试,并且通常数据处理管道具有弹性和性能。
弹性
RustFS 通过对每个对象使用内联纠删码来保护数据,这比从未被采用的 HDFS 复制替代方案要高效得多。此外,RustFS 的位腐 (bitrot) 检测确保它永远不会读取损坏的数据 —— 它能动态地捕获并修复对象的损坏数据。RustFS 还支持跨地域 (cross-region) 与主动-主动 (active-active) 的复制。最后,RustFS 支持完整的对象锁定框架,提供法律保留和保留(具有治理和合规模式)。
软件定义
Hadoop HDFS 的继任者并非硬件设备,而是一套运行在通用硬件上的软件。这正是 RustFS 的本质 ―― 软件。与 Hadoop HDFS 类似,RustFS 旨在充分利用通用服务器。由于能够利用 NVMe 驱动器和 100 GbE 网络,RustFS 可以缩小数据中心规模,从而提高运营效率和可管理性。事实上,正在构建替代型数据湖的公司在减少 60% 或更多的硬件占用的同时提升性能、并降低管理它们所需的全职员工(FTEs)。
安全
RustFS 支持多种复杂的服务端加密方案,以保护数据无论其存储于何处,不论数据在传输中还是静止状态。RustFS 的方法确保了机密性、完整性和真实性,且性能开销可以忽略不计。通过支持 AES-256-GCM、ChaCha20-Poly1305 和 AES-CBC 的服务器端和客户端加密,确保了应用程序的兼容性。此外,RustFS 还支持业界领先的密钥管理系统(KMS)。